
[논문리뷰]
ABSTRACT
- 이전의 학습 방법보다 깊은 네트워크의 학습을 좀 더 용이하게 하기 위한 프레임워크를 제시한다.
- Residual networks가 최적화하기 더 쉽고, Depth가 증가된 모델에서도 상당히 증가된 정확도를 얻을 수 있음을 보여준다.
INTRODUCTION
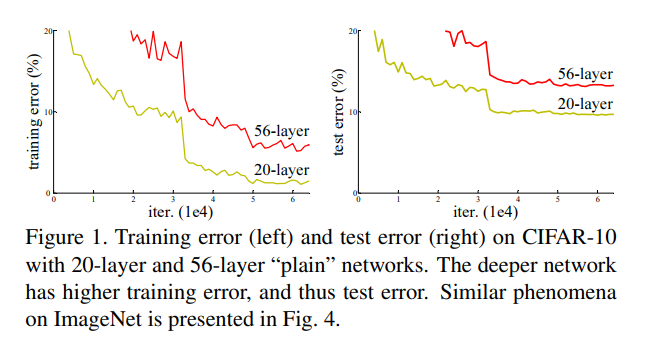
- Is learning better networks as easy as stacking more layers?
- 더 나은 네트워크를 학습하는 것이 더 많은 계층을 쌓는 것만큼 쉬운가?
- 위 그림에서 layer가 더 깊은 빨간색이 error가 더 높은 것을 확인할 수 있다.
- layer가 깊어질수록 gradient가 vanishing/exploding 하는 문제가 존재한다.
- 이 문제는 normalized initialization, batch normalization 등으로 해결이 가능하다.
- 네트워크의 깊이가 증가하면 accuracy가 saturated한 상태가 되고 그 이후 빠르게 감소된다.
- 이 문제는 과적합의 문제가 아니며, 더 많은 레이어를 추가하면 발생하는 문제이다.
- 더 얕은 모델과 더 많은 layer를 추가한 모델을 고려하면 추가된 layer는 identity mapping이고, 다른 layer는 학습된 얕은 모델에서 복사된다. 따라서 더 깊은 모델이 더 얕은 모델보다 더 높은 training error를 생성하지 않아야한다. 그러나 실험에 따르면 현재 더 나은 솔루션을 찾을 수 없다.
Deep Residual Learning
Residual Learning
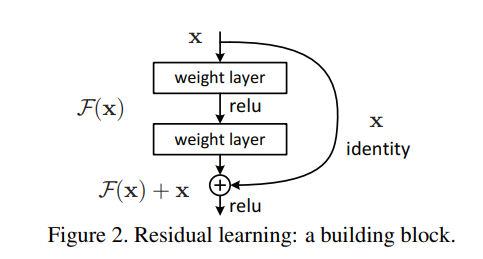
- 본 논문에서는 deep residual learning framework를 제안하여 degradation 문제를 해결한다.
- ResNet의 Residual Learning은 H(x)가 아닌 출력과 입력의 차인 H(x) - x를 얻도록 목표를 수정
- Residual Function인 F(x) = H(x) - x를 최소화해야한다. 즉, 출력과 입력의 차이를 줄인다는 의미이다.
- 여기에서 x는 도중에 변경이 불가능한 입력값이므로 F(x)가 0이 되는 것이 최적의 해이다. 따라서 H(x) = x, H(x)를 x로 mapping 하는 것이 학습의 목표가 된다.
- 이전에는 알지 못하는 최적의 값으로 H(x)를 근사시켜야 해서 어려움이 있었는데, 이제는 H(x) = x라는 최적의 목표값이 존재하기에 F(x)의 학습이 더욱 쉬워진다.
Identity Mapping
$ y = F(x, {W_i}) + x. $
- x와 y는 인풋과 아웃풋 벡터이다.
- Function $ F(x,{W_i}) $는 학습될 residual mapping을 나타낸다.
- $ F = W_2\sigma(W_1x) $ 에서 $ \sigma $는 ReLU를 나타낸다.
- $ F + x $는 shortcut connection와 element-wise addition에 의해 수행된다.
- 위 수식에서는 x와 F의 차원이 같다.
- 파라미터 수와 계산 복잡도를 증가시지 않는다는 장점이 있다.
$ y = F(x, {W_i}) + W_s x $
- 차원이 같이 않을 경우 Shortcut connection에 정사각형 행렬 W_s를 사용할 수 있다.
Network Atrchitectures
- Plain nets과 Residual nets을 비교하였다.

- input과 output dimension이 다른 경우 점선으로 표시한다.
Implementation
- mini-batch(256 size) SGD 사용
- learning rate는 0.1부터 시작하여 error가 안정되면 10으로 나눔
- 0.0001의 weight decay와 0.9의 momentum을 사용
- Convolution 직후와 Activation 이전에 batch normalization을 수행
Experiments
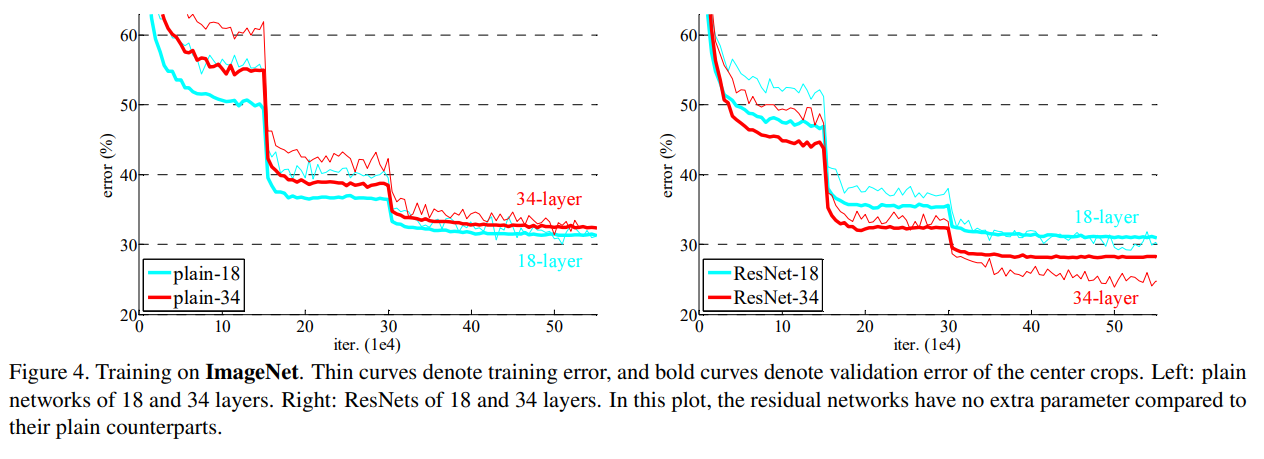
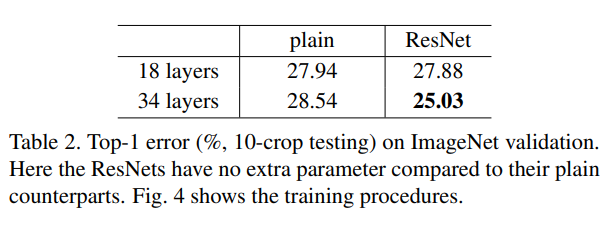
- Plain Networks : 34-layer가 더 높은 error를 보인다.
- training error도 높았기 때문에 degradation 문제가 있다고 판단
- 이러한 최적화 문제는 Vanishing gradient 때문에 발생하는 것은 아니라 판단 -> plain 모델은 batch normalization이 적용되어 순전파 과정에서 variance는 0이 아니며, 역전파 과정에서의 기울기 또한 잘 나타냈기 때문
- exponentially low convergence rate를 가지기 때문에 training error의 감소에 좋지 못한 영향을 끼쳤을 것이라 추측함.
- Residual Networks : 베이스라인은 Plaine net과 동일하게 진행하였다. 결과적으로 34-layer가 더 낮은 error를 보였다.
- Shortcut connection이 각 3 x 3 필터에 추가되었다.
- 모든 shortcuts에 identity mapping을 사용하였고 차원 증가를 위해 zero-padding을 사용하였다.
- 따라서 plain과 비교했을 때 추가적인 파라미터가 없다.
Identity vs Projection Shortcuts
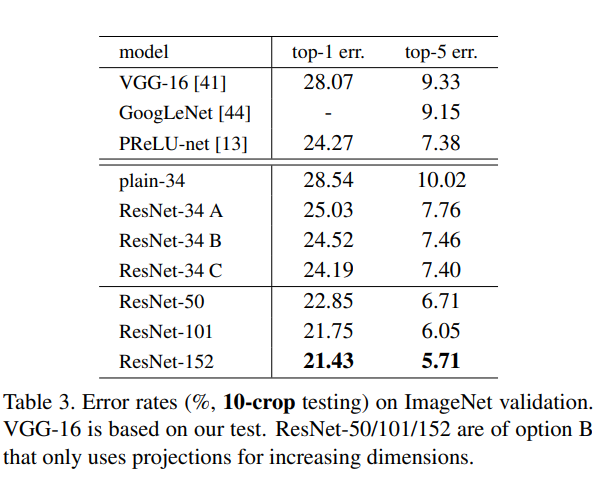
- identity shortcuts이 training에 도움이 된다는 것을 확인하였다. 따라서 다음으로 projection shortcuts에 대해 조사하였다.
- (A) 증가하는 차원에 대해 zero-padding shortcut, 모든 shortcut은 parameter free
- (B) 증가하는 차원에 대해 Projection shortcut 적용, 그렇지 않으면 identity shortcut 적용
- (C) 모든 경우에 Projection shortcut 적용
- (B)가 (A)보다 미세하게 더 좋았다. -> A의 zero-padding 차원상 사실상 residual-learning이 아니기 때문이라 추측
- (C)가 (B)보다 미세하게 더 좋았다. -> Projection shortcut에 의해 추가적인 파라미터가 생겼기 때이라고 추측
- 메모리/시간 복잡도와 모델의 사이즈를 줄이기 위해 (C)는 사용하지 않기로 결정하였다.
- (A)(B)(C) 간의 미세한 차이는 projection shortcut은 degradation 문제를 다루는데 중요한 요소가 아님을 알 수 있다.
Deeper Bottleneck Architectures
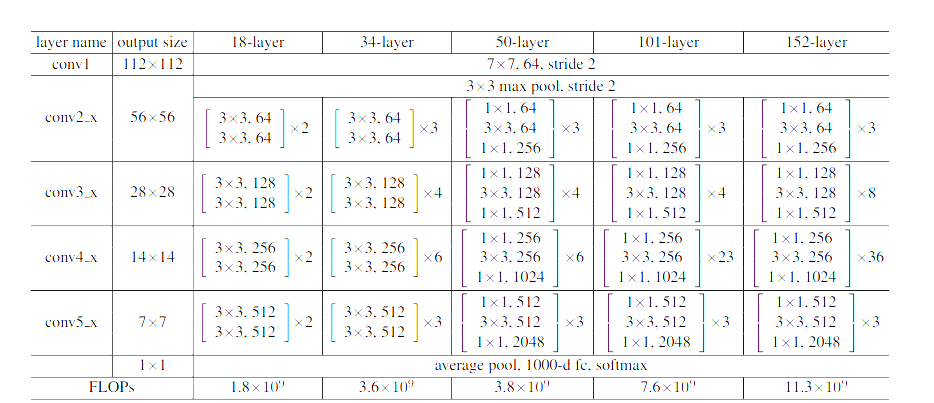
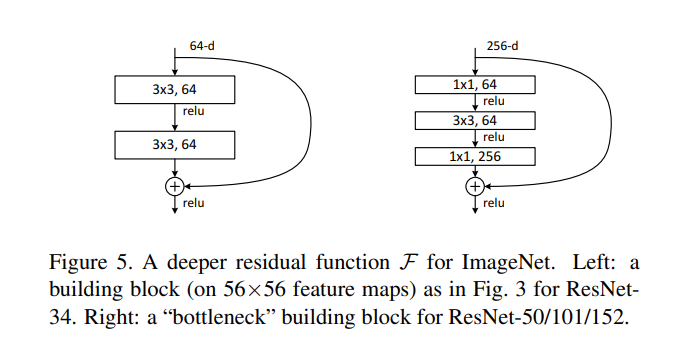
- layer를 쌓을수록 dimension의 크기가 커짐에 따라, 파라미터의 수가 많아지고 복잡도가 증가한다. 이를 해결하기 위해 bottleneck architecture를 사용하였다.
- 학습에 투자할 수 있는 시간을 고려해야 하기 때문에, building block을 bottleneck 디자인으로 수정하였다.
- 2개의 layer 대신 3개의 layer stack을 사용하였다.
- 1 x 1 layer는 차원을 줄이고 늘리는 역할
- 3 x 3 layer는 더 작은 input과 output 차원의 bottleneck 구조를 만들어준다.
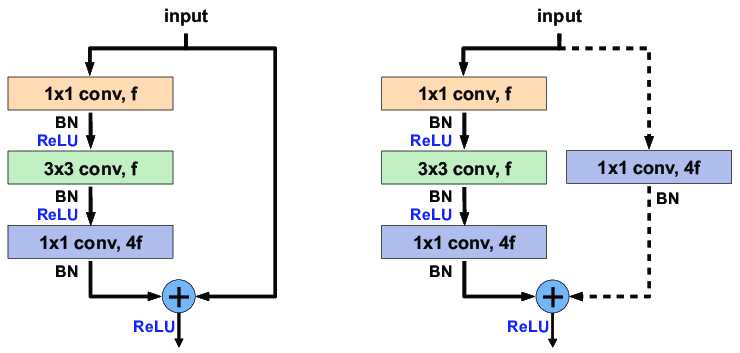
- 여기서 parameter-free인 identity shortcut은 bottleneck 구조에서 특히 중요하다. 만약 identity shortcut이 projection shortcut으로 대체되면 shortcut이 2개의 고차원 출력과 연결되기 때문에, 모델의 복잡도와 크기가 2배가 된다. 따라서 identity shortcut이 bottleneck 디자인에서 효율적인 모델로 이끌어준다.
- 실험 결과 152 layer까지도 34 layer보다 더 정확함.
Conclusion
- 결과적으로 residual learning을 도입한 Resnet을 통해 깊이가 증가함에 따라 error가 감소하고, plain network보다 좋은 성능을 보여준다.
- degration 문제를 해결함
- 기존의 mapping보다 optimize하기 쉽다. (H(x) = F(x) + x)
- 기존의 model보다 더 깊은 layer와 적은 파라미터를 통해 빠른 훈련 속도를 가진다.
'Paper Review' 카테고리의 다른 글
[논문리뷰]
ABSTRACT
- 이전의 학습 방법보다 깊은 네트워크의 학습을 좀 더 용이하게 하기 위한 프레임워크를 제시한다.
- Residual networks가 최적화하기 더 쉽고, Depth가 증가된 모델에서도 상당히 증가된 정확도를 얻을 수 있음을 보여준다.
INTRODUCTION
- Is learning better networks as easy as stacking more layers?
- 더 나은 네트워크를 학습하는 것이 더 많은 계층을 쌓는 것만큼 쉬운가?
- 위 그림에서 layer가 더 깊은 빨간색이 error가 더 높은 것을 확인할 수 있다.
- layer가 깊어질수록 gradient가 vanishing/exploding 하는 문제가 존재한다.
- 이 문제는 normalized initialization, batch normalization 등으로 해결이 가능하다.
- 네트워크의 깊이가 증가하면 accuracy가 saturated한 상태가 되고 그 이후 빠르게 감소된다.
- 이 문제는 과적합의 문제가 아니며, 더 많은 레이어를 추가하면 발생하는 문제이다.
- 더 얕은 모델과 더 많은 layer를 추가한 모델을 고려하면 추가된 layer는 identity mapping이고, 다른 layer는 학습된 얕은 모델에서 복사된다. 따라서 더 깊은 모델이 더 얕은 모델보다 더 높은 training error를 생성하지 않아야한다. 그러나 실험에 따르면 현재 더 나은 솔루션을 찾을 수 없다.
Deep Residual Learning
Residual Learning
- 본 논문에서는 deep residual learning framework를 제안하여 degradation 문제를 해결한다.
- ResNet의 Residual Learning은 H(x)가 아닌 출력과 입력의 차인 H(x) - x를 얻도록 목표를 수정
- Residual Function인 F(x) = H(x) - x를 최소화해야한다. 즉, 출력과 입력의 차이를 줄인다는 의미이다.
- 여기에서 x는 도중에 변경이 불가능한 입력값이므로 F(x)가 0이 되는 것이 최적의 해이다. 따라서 H(x) = x, H(x)를 x로 mapping 하는 것이 학습의 목표가 된다.
- 이전에는 알지 못하는 최적의 값으로 H(x)를 근사시켜야 해서 어려움이 있었는데, 이제는 H(x) = x라는 최적의 목표값이 존재하기에 F(x)의 학습이 더욱 쉬워진다.
Identity Mapping
$ y = F(x, {W_i}) + x. $
- x와 y는 인풋과 아웃풋 벡터이다.
- Function $ F(x,{W_i}) $는 학습될 residual mapping을 나타낸다.
- $ F = W_2\sigma(W_1x) $ 에서 $ \sigma $는 ReLU를 나타낸다.
- $ F + x $는 shortcut connection와 element-wise addition에 의해 수행된다.
- 위 수식에서는 x와 F의 차원이 같다.
- 파라미터 수와 계산 복잡도를 증가시지 않는다는 장점이 있다.
$ y = F(x, {W_i}) + W_s x $
- 차원이 같이 않을 경우 Shortcut connection에 정사각형 행렬 W_s를 사용할 수 있다.
Network Atrchitectures
- Plain nets과 Residual nets을 비교하였다.
- input과 output dimension이 다른 경우 점선으로 표시한다.
Implementation
- mini-batch(256 size) SGD 사용
- learning rate는 0.1부터 시작하여 error가 안정되면 10으로 나눔
- 0.0001의 weight decay와 0.9의 momentum을 사용
- Convolution 직후와 Activation 이전에 batch normalization을 수행
Experiments
- Plain Networks : 34-layer가 더 높은 error를 보인다.
- training error도 높았기 때문에 degradation 문제가 있다고 판단
- 이러한 최적화 문제는 Vanishing gradient 때문에 발생하는 것은 아니라 판단 -> plain 모델은 batch normalization이 적용되어 순전파 과정에서 variance는 0이 아니며, 역전파 과정에서의 기울기 또한 잘 나타냈기 때문
- exponentially low convergence rate를 가지기 때문에 training error의 감소에 좋지 못한 영향을 끼쳤을 것이라 추측함.
- Residual Networks : 베이스라인은 Plaine net과 동일하게 진행하였다. 결과적으로 34-layer가 더 낮은 error를 보였다.
- Shortcut connection이 각 3 x 3 필터에 추가되었다.
- 모든 shortcuts에 identity mapping을 사용하였고 차원 증가를 위해 zero-padding을 사용하였다.
- 따라서 plain과 비교했을 때 추가적인 파라미터가 없다.
Identity vs Projection Shortcuts
- identity shortcuts이 training에 도움이 된다는 것을 확인하였다. 따라서 다음으로 projection shortcuts에 대해 조사하였다.
- (A) 증가하는 차원에 대해 zero-padding shortcut, 모든 shortcut은 parameter free
- (B) 증가하는 차원에 대해 Projection shortcut 적용, 그렇지 않으면 identity shortcut 적용
- (C) 모든 경우에 Projection shortcut 적용
- (B)가 (A)보다 미세하게 더 좋았다. -> A의 zero-padding 차원상 사실상 residual-learning이 아니기 때문이라 추측
- (C)가 (B)보다 미세하게 더 좋았다. -> Projection shortcut에 의해 추가적인 파라미터가 생겼기 때이라고 추측
- 메모리/시간 복잡도와 모델의 사이즈를 줄이기 위해 (C)는 사용하지 않기로 결정하였다.
- (A)(B)(C) 간의 미세한 차이는 projection shortcut은 degradation 문제를 다루는데 중요한 요소가 아님을 알 수 있다.
Deeper Bottleneck Architectures
- layer를 쌓을수록 dimension의 크기가 커짐에 따라, 파라미터의 수가 많아지고 복잡도가 증가한다. 이를 해결하기 위해 bottleneck architecture를 사용하였다.
- 학습에 투자할 수 있는 시간을 고려해야 하기 때문에, building block을 bottleneck 디자인으로 수정하였다.
- 2개의 layer 대신 3개의 layer stack을 사용하였다.
- 1 x 1 layer는 차원을 줄이고 늘리는 역할
- 3 x 3 layer는 더 작은 input과 output 차원의 bottleneck 구조를 만들어준다.
- 여기서 parameter-free인 identity shortcut은 bottleneck 구조에서 특히 중요하다. 만약 identity shortcut이 projection shortcut으로 대체되면 shortcut이 2개의 고차원 출력과 연결되기 때문에, 모델의 복잡도와 크기가 2배가 된다. 따라서 identity shortcut이 bottleneck 디자인에서 효율적인 모델로 이끌어준다.
- 실험 결과 152 layer까지도 34 layer보다 더 정확함.
Conclusion
- 결과적으로 residual learning을 도입한 Resnet을 통해 깊이가 증가함에 따라 error가 감소하고, plain network보다 좋은 성능을 보여준다.
- degration 문제를 해결함
- 기존의 mapping보다 optimize하기 쉽다. (H(x) = F(x) + x)
- 기존의 model보다 더 깊은 layer와 적은 파라미터를 통해 빠른 훈련 속도를 가진다.